
CogViS stands for Cognitive Vision Systems.
Please visit the project's main web-site at http://cogvis.nada.kth.se/ for additional information.
[Introduction] [Mailinglists] [Bibliography] [Video] [Projects]Three mailing lists local to KOGS/CSL have been created, these are
For internal use, there's also a repository of many mails send to the cogvis list, and in particular all the protocols written.
[Introduction] [Mailinglists] [Bibliography] [Video] [Projects]As part of CogViS an annotated Bibliography will be created. This will use BibTeX as its back-end, and the CSL-Part will be search-able here. If you are working from inside CSL you can also edit it online by clicking here.
[Introduction] [Mailinglists] [Bibliography] [Video] [Projects]As part of CogViS we set up an environment which allows us to capture images from 3 synchronised video-cameras at a resolution of 1024x779 and a frame-rate of up to 38 frames per second. Up to 32 minutes of consecutive frames can be grabbed using this setup.

We are using 2 1-chip RGB (Bayer filter) cameras DFD-5013-HS, and one monochrome camera DMD-5013-HS. The cameras use a 10-bit LVDS signal for video-out, which allows the capture of non-interlaced images exceeding the maximum size of the PAL or NTSC standards most analogue cameras adhere to.
Each camera is connected to a Matrox Meteor II/Dig digital framegrabber in a dedicated PC running Windows NT 4.0. The PCs use a Gigabyte GA 7VTXE+ Socket A mainboard with an AMD Athlon XP 1800+ processor (at 1533MHz). Each PC has two IBM 61.4GB HDD IC35L060 (we used the c't's HDD-benchmark H2Benchw to time disk-writes. These tests show that only the first 50% of the disk are fast enough for our purpose, i.e. a sustained write-rate of more than 15MB/s), each one as master on it's own UDMA100 IDE channel (although a Teac CD-540E CD-ROM drive is also connected to one of them as a slave).
For synchronised capture, the output of a function generator (5V peak-to-peak square pulse) is connected with the TTL trigger-input of all three framegrabbers.
As the Matrox Meteor II/Dig ships with it's own library, but without much precompiled (or even only prewritten) software, we had to write our own routines for sequence capture. Basically, these use two separate threads to
As there seems to be a bug in the official synchronisation-mechanism (i.e. the end of a grab is signalled long before the actual image was written to memory) we simply make sure that grabbing precedes writing by at least three images. We use a ringbuffer of 128 images, but so far haven't encountered any need for a buffer of more than 12 images in practice. The actual source-code can be obtained from Sven Utcke (anybody working at KOGS/CSL can also look here for more information).
[Introduction] [Mailinglists] [Bibliography] [Video] [Projects]This will give an overview over the different approaches taken within our group.
As mentioned above, we use up to 3 synchronised cameras to take image-sequences of our sample scene. These need to be calibrated, so that:

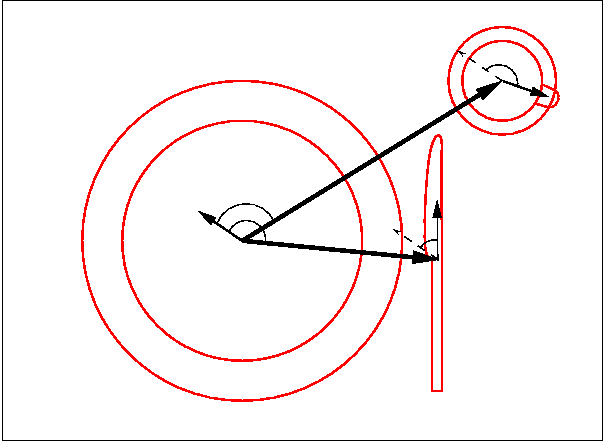
Yildirim Karal, a student of Hamburg University, is working on both aspects for his 3rd year project ("Studienarbeit"). As of Nov. 2002 he is developing the algorithms for the lens calibration. So far he can take an image of chequered paper under an arbitrary angle (Figure a), find the pixels belonging to lines by adaptive thresholding (Figure b) and find approximate lines through these points by Hough-transform (Figure c+d). These will be used to determine an approximation of the angle of projection and from there both the exact angle of projection and the lens-distortion simultaneously.
 |
 |
 |
 |
| a) | b) | c) | d) |
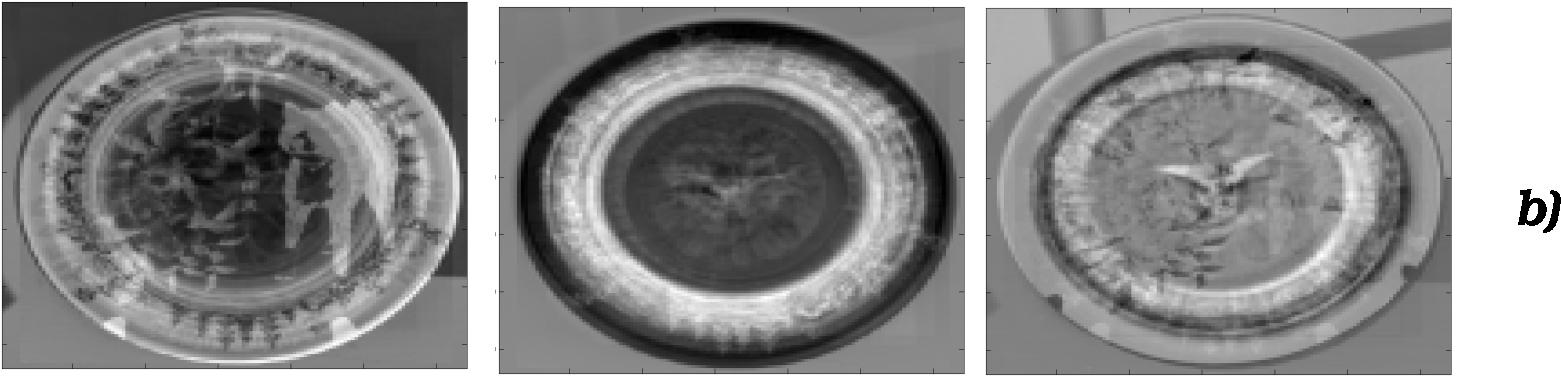
 As CogVis will need to be able to regonize a large number of
different objects and from differen positions even for our
relatively simple szenario, we decided to use appearance based
methods for the actual recognition. Joshua Buttkus is a 4th year
student working for us on a contract basis. He is currently
implemeting standard eigenfaces, experimenting mostly with plates
at the moment, and will expand this to anti-faces in the near
future. A short example (for plates) is given below:
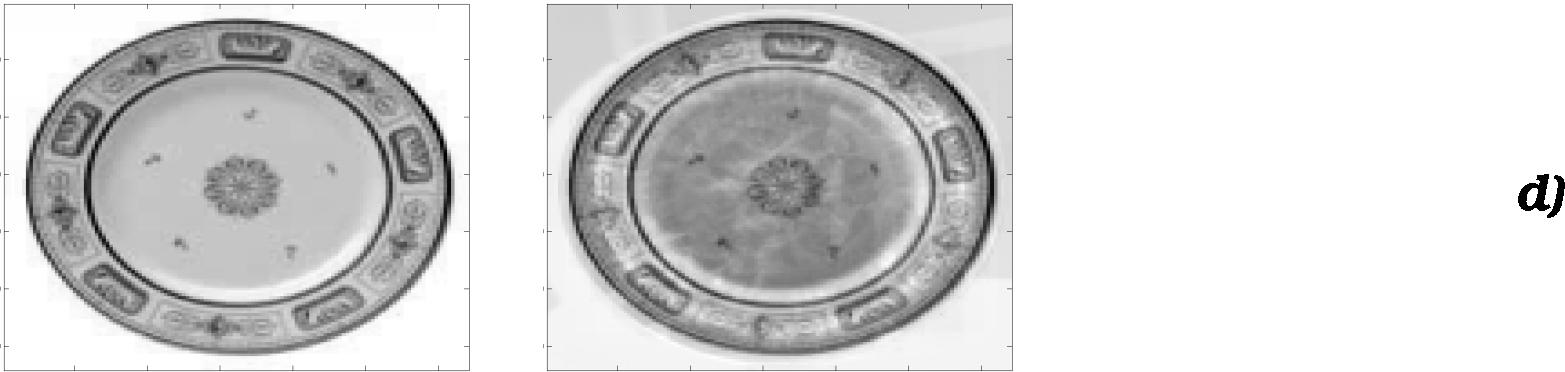
As CogVis will need to be able to regonize a large number of
different objects and from differen positions even for our
relatively simple szenario, we decided to use appearance based
methods for the actual recognition. Joshua Buttkus is a 4th year
student working for us on a contract basis. He is currently
implemeting standard eigenfaces, experimenting mostly with plates
at the moment, and will expand this to anti-faces in the near
future. A short example (for plates) is given below:


This is another 3rd-year project, trying to develope simple blob-tracking, not unlike the Leeds tracker, but using a different colour space. So far, only a static background is used in background substraction, but this already gives rather promising results (if you ignore, for a moment, the guy who was standing in the top left corner of the background image :-).
| Bayer Images: |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| RGB Images: |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Difference Images: |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
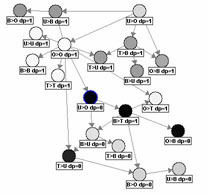 For his Master thesis ("Diplomarbeit") Peter Lueders is working on learning
probabilistic models describing sequences of actions. The work is
focussed on Bayesian networks and Bayesian clustering by dynamics.
For his Master thesis ("Diplomarbeit") Peter Lueders is working on learning
probabilistic models describing sequences of actions. The work is
focussed on Bayesian networks and Bayesian clustering by dynamics.
Typical high-level concepts which must be recognized in high-level vision are composed of multiple objects underlying temporal and spatial constraints. Our guiding example is "setting the table" which is modelled as a concept composed of loosely coordinated individual placement actions. The idea is to learn such a concept from observations. We investigate both supervised and unsupervised learning techniques.
 One major aspect of the CogVis project is the question how to reason
about spacial relations. Therefore Peer Stelldinger, who is a
PhD-student paid by the University of Hamburg, is working on a
module which allows to learn and reason about spacial configurations
of objects on the table.
One major aspect of the CogVis project is the question how to reason
about spacial relations. Therefore Peer Stelldinger, who is a
PhD-student paid by the University of Hamburg, is working on a
module which allows to learn and reason about spacial configurations
of objects on the table.
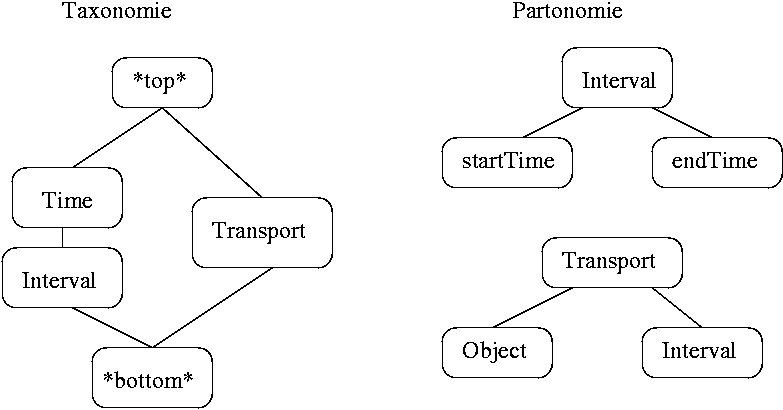 Steffen Maas is a student from the University of Rostock on an
internship in the Cogvis project, working on ontology-based
high-level interpretation tasks. Currently he is creating a
common sense ontology, formulated in standardised knowledge
representation languages, like OWL, DAML-Oil, etc.
Steffen Maas is a student from the University of Rostock on an
internship in the Cogvis project, working on ontology-based
high-level interpretation tasks. Currently he is creating a
common sense ontology, formulated in standardised knowledge
representation languages, like OWL, DAML-Oil, etc.